Neat GitHub Actions patterns for GitHub Merge Queues
GitHub have enabled their “merge queue” function, which is really exciting! The “it’s not rocket science rule” of software development is a pretty good guiding principle for developing stuff in a team (if CI is fast, more on that later!) - so I’m very glad it gets easier to achieve.
Unfortunately, it’s only “easier” but not “easy”. I was able to use the feature for about a half year while it was in private beta, and while using it my team and I learned a few lessons that make certain things possible (and some others easier).
Some reasons to run a merge queue
There are several use cases for a merge queue, and GitHub merge queues (GHMQ from now on) make some easy and some pretty annoying to achieve. Here are a few I can think of:
- A repository that passes all tests - this is the “not rocket science” goal. GHMQs make this a single checkbox on a branch protection rule. This is easy to achieve.
- A way to see, end-to-end, where in the CI process a change is. GHMQs don’t exactly make this impossible, but oddly enough, turning on the merge queue makes it harder to see the progress a change is making along that merge queue.
- A way to optimize time spent running tests - when you run a merge queue like bors, you can split CI into two parts: One, running unconditionally for all changes in a PR (answering the question “does this have a chance of passing CI”); and one that runs only when a designated reviewer decides to run the entire test suite. GHMQs make this difficult.
So, there’s one thing that GHMQs succeed at: The brief. If “It’s not rocket science” is the entirety of the job, they do it! But unfortunately, developers are impatient1 in two ways: they want to know when to expect their changes to land, and they want that to be very soon.
This is now getting noticed by folks, and so I would like to write up what I’ve learned that makes the impatience situation easier.
Improving the UX of merge queues with some GitHub Actions tricks
This whole thing I’m going to write only applies if you run your CI through GitHub Actions (GHA); if you don’t, there may still be a way to do what you need! But the way that external statuses are reported can’t be worked with in GHA the way we need. You may still find inspiration for a solution in the following sections.
Running a “second round of tests” on the merge queue only
As mentioned above, having a second round of tests that run only when developers intend to merge their change really helps reduce the turnaround time for a change (and reduce costs when running CI!). Unfortunately, the way GHMQs work, it’s not wholly obvious how to do that unless you spent literal days reading their docs (I was working on the GHMQ stuff as a “side project” at work and it took me about 2 weeks to come up with this solution).
The easiest (and only) way I know of to achieve a second round of tests is defining a set of jobs: that “gather” up other jobs’ outcomes and use some logic to decide if they are relevant in the current “round”. Only these “gatherer” jobs get to be required statuses on the branch protection rule. Their dependents can be in turn be conditionally run, depending on the “round”.
Defining jobs that “gather” up other jobs’ statuses
GHA jobs can define a list of other jobs they “need” before they can start. This is the key for our solution. Here’s a job that (naively) runs after two other jobs named “tests” and “lints” have run, and if they have passed, passes in turn (naively):
# Beware! This is a naive non-solution!
jobs:
# ...
can_merge:
needs: [tests, lints]
runs-on: "ubuntu-latest"
steps:
- name: yay
run: |
echo success
This feels too easy. If you didn’t notice the comment, you might have glanced at the scroll bar and noticed that there’s a lot of article left to go. Yes. Of course there’s a catch.
GitHub Actions that have a skipped action on their “needs” list are skipped in turn. This isn’t so bad if “tests” passes but “lints” gets skipped. But if “tests” fails, your job will be skipped, which counts as a successful status! You can add if: always() to the job - but then the above job will also run (and pass!) even if any of its dependencies have failed. All that would be a massive violation of the “not rocket science” principle of having a code repo that always passes tests. Oops!
So, what can we do? We’re programmers, we can always add more logic. Here’s an action that always runs, but when it runs, checks the status of its “needed” jobs & only succeeds if the required criteria hold:
jobs:
# ...
can_merge:
needs: [tests, lints]
if: always()
permissions:
actions: read
runs-on: ubuntu-latest
steps:
- env:
NEEDS_JSON: "${{toJSON(needs)}}"
name: Transform outcomes
run: |
echo "ALL_SUCCESS=$(echo "$NEEDS_JSON" | jq '. | to_entries | map([.value.result == "success", .value.result == "skipped"] | any) | all')" >>$GITHUB_ENV
- name: check outcomes
run: "[ $ALL_SUCCESS == true ]"
Now that’s a bit more complicated, but you’ll notice that it’s all based on information that GHA passes to the job (with the appropriate permission)! We’re not curling weird github API endpoints here.
If you’re wondering what’s going on in that jq above, it’s pretty much the following: “Take the result of all the jobs given on needs, then see if each has one of the statuses ‘success’ or ‘skipped’. Emit true if this is true for all jobs.”
Then the last step “check outcomes” verifies that all jobs have succeeded (or been skipped), and only if they have, exits with a successful status.
Why allow for “skipped”, you may ask - we’ll get to that now.
Not running all jobs in the first round of tests
So let’s say you have a job expensive_checks that you want to ensure has succeeded before a change gets merged to your default branch, but it takes 20 minutes to run… so you’d like to only run it when the merge queue gets triggered. We can use GHA workflows’ if: for that!
Here’s a more or less complete workflow:
on:
- merge_group:
- pull_request:
jobs:
tests:
# ...
lints:
# ...
expensive_checks:
if: github.event_name == 'merge_group'
# ...
can_enqueue:
needs: [tests, lints]
if: always() && github.event_name != 'merge_group'
permissions:
actions: read
runs-on: ubuntu-latest
steps:
- env:
NEEDS_JSON: "${{toJSON(needs)}}"
name: Transform outcomes
run: |
echo "ALL_SUCCESS=$(echo "$NEEDS_JSON" | jq '. | to_entries | map([.value.result == "success", .value.result == "skipped"] | any) | all')" >>$GITHUB_ENV
- name: check outcomes
run: "[ $ALL_SUCCESS == true ]"
can_merge:
needs: [tests, lints, expensive_checks]
if: always() && github.event_name == 'merge_group'
# Same thing as above, from here on:
permissions:
actions: read
runs-on: ubuntu-latest
steps:
- env:
NEEDS_JSON: "${{toJSON(needs)}}"
name: Transform outcomes
run: |
echo "ALL_SUCCESS=$(echo "$NEEDS_JSON" | jq '. | to_entries | map([.value.result == "success", .value.result == "skipped"] | any) | all')" >>$GITHUB_ENV
- name: check outcomes
run: "[ $ALL_SUCCESS == true ]"
Sidenote: Ugh, this is a lot of duplication; is there a way you can make this less duplicate-y? Not really. Maybe you’ll want to template this via something that codegens. Or it would be possible to publish the logic as a third-party action, but I feel this entire duplicated piece of code is short enough that you have a cheap-enough way to minimize third-party risk by just keeping the two bits next to each other in a file.
Notice the if: clauses on the various test/lint/etc jobs above! These ensure that only the non-expensive jobs run outside the merge queue (the github.event_name != 'merge_group' criteria).
That’s in contrast to the if: clauses on the can_merge and can_enqueue jobs: The can_merge job is set to only be active for runs triggered by the merge queue - otherwise it reports a “skipped” status & counts as a success. Its depended-on jobs will still run, unless you add if: clauses to those jobs directly. The same applies, vice-versa, to the can_enqueue status. It doesn’t report a status on the merge queue, but does on any other run (so that the faster tests can prevent an entry to the merge queue).
Putting it all together
Now that you have GHA jobs that have the appropriate statuses on the merge queue & before it, gathered from the appropriate jobs, you can make them required for the merge queue workflow. Once you’re ready to make this official, remove all the required statuses from your branch protection rule’s set of required statuses and add both can_enqueue and can_merge as required statuses. It looks like this:
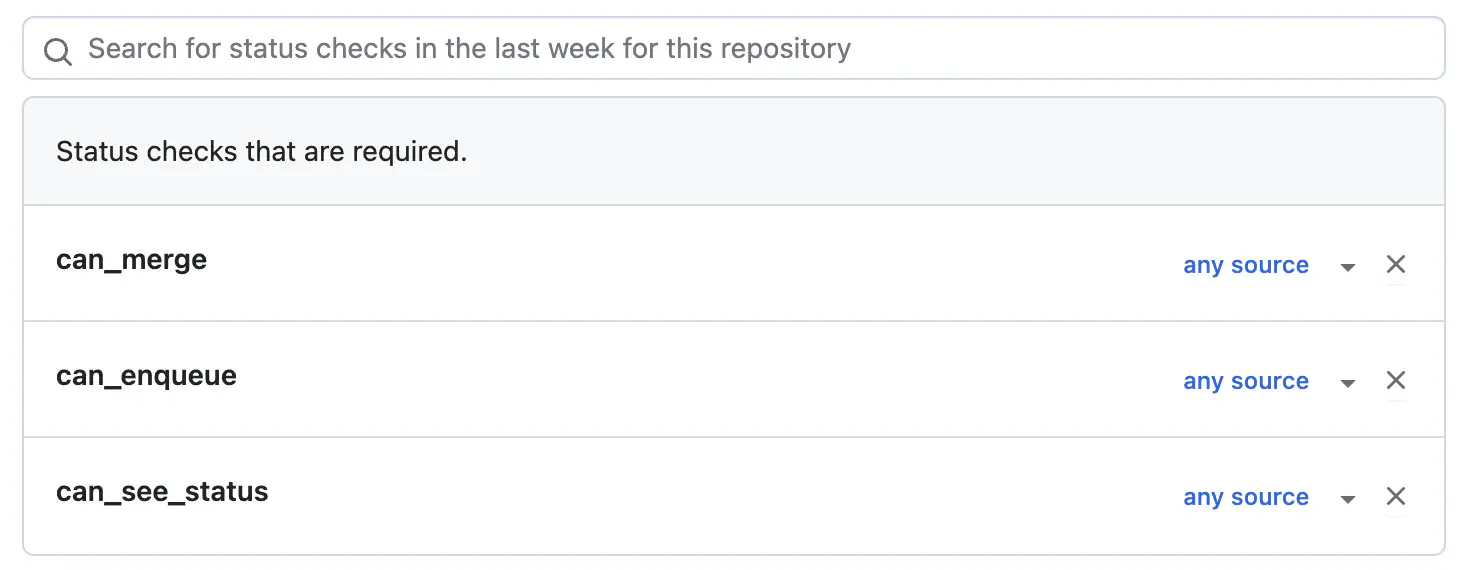
But wait, what is that can_see_status thing?
Working around some GHMQ UX issues
When a PR is added to the merge queue, the statuses of that change look like the following image:

…which does not have a link to any of the jobs concretely being run. That’s the downside of these jobs with other jobs on their “needs” list: Until all these jobs have finished, GHA doesn’t schedule them! So there’s nothing to link, and you don’t see any status.
There exists a very quick and easy work-around though: Add a job that lives next to can_merge and can_enqueue that passes ~immediately as a required status check:
jobs:
can_see_status:
runs-on: ubuntu-latest
steps:
- name: "Immediate success"
run: true
If you add that job’s name to the list of required branch protection statuses, you will get a direct link to the github actions workflow being run, and from there it’s just a few clicks until you see the concrete test status.
Conclusion
This concludes my walk-through of the solution to the “second round of tests” problem with Github Merge Queues. I hope you find it useful. I’ve got a few working examples (code-generated) in the github repo for tsnsrv.
All that is a lot of YAML, but when you structure GHA CI like that, it can save you time and money (by not running as many tests over and over, while still ensuring that the protected branch stays CI-passing). Could GitHub make this easier for us? I think they could. I wish they did.
“We will encourage you to develop the three great virtues of a programmer: laziness, impatience, and hubris.” – Larry Wall, Programming Perl ↩︎